
GIF showing the RL agent (left-side) playing against the human player (right-side): collect more fruit (reward) than your opponent and reach the goal before your opponent does.
Click here to play the demo
Background
I was interested in RL around 2016 when AlphaGo came along. It was one of those ‘aha’ moments watching how a machine was able to beat a human in one of the most difficult board games.
Over the years, I started poking around RL by reading the classic Sutton & Barto textbook, watching David Silver’s 2018 lectures @ UCL and of course, Karpathy’s Pong from Pixels.
With the impact of AlphaGo/Zero as well as OpenAI Five, I was curious how exactly RL was used in games. The only current-ish games that use RL as part of their core gameplay were Peter Stone et al’s Sophy AI and Naruto Mobile (discounting some RL-based games from decades ago).
It was rather disappointing that one of the most crucial algorithms that was borne out of games had very little impact on actual playable games. RL of course has a wide variety of important uses in robotics, drones, etc as well as with the recent craze around LLMs (RLVR/RLHF).
This is where I thought, “perhaps I could build a playable demo/toy game that could use RL as a core gameplay agent?”.
That’s also right around the time I discovered the excellent Puffer AI library by Joseph Suarez an (mostly) one-man army chipping away at making RL accessible to the rest of us.
Building a Pixel Platformer demo
I am building a 2D pixel platformer demo to train an RL agent to play alongside you. I also wanted the game to be standalone without an RL agent, so self-play (i.e. playing against a version of yourself) was a key game mechanic.
I had the following properties/goals in mind:
- Self-play as a core game mechanic
- Game should be RL trainable
- Should be fun/playable by a human
I will expand on two important properties/goals:
Self-play as a core game mechanic
I am a fan of rogue-likes such as Spelunky 2 that have infinite playability (when you die, you go back to level 1 that is randomly/procedurally generated). I wanted to explore a different kind of infinite playability that also meshed well with RL.
Here’s how I structure self-play:
- A level/map in the platformer is essentially a mirrored level, with Player 1 (You) on the left-side.
- You play multiple rounds of the same level.
- As you reach the goal and proceed to the next round (same map/level), you switch sides:
- Player 2 (You) play against a ghost / self-play copy of your previous round as Player 1.

I found this to be a fun game mechanic as you could keep playing against ‘yourself’ (or against others’, or against an RL agent). This also helps the game scale during RL training (as it is an important reward signal).
RL Trainable
Most game+RL training that you might come across use some sort of Rube Goldberg contraption to run a simulation in a very slow environment, capture the pixels and train RL. This is of course a very slow and cumbersome process (especially as you consider things like rendering FPS and time-based logic). Typically, you would see something like this as part of the training:

Pixels are gnarly: There are too many of them (millions!), colors may not mean anything, and offscreen data requires separate handling. Why go through all the trouble of a machine having to render all these pixels, grabbing the framebuffer, feeding it to another machine/program to train/run inference? …When the machine has the full internal state before it generates the pixels.
My pixel platformer demo here is built ground-up to ensure:
- You don’t need pixels. The game state is built ground-up to serve as observations for RL.
- Don’t render anything during training.
- And ensure deterministic state transformations (time/randomness are controlled).
A nice property of this is I can now train this pixel platformer (on a commodity nVidia graphics card from years ago) @ 100K-150K FPS (or in RL terminology, steps per second), with the entire training run taking ~2 hours. Here is what the arch looks like during inference:

This requires far fewer observations (compared with a pixel-based system) and hence in general is much faster to run, train, infer and so on. I encode each ‘block’ in the game as an observation (relative to the player/agent), and adding new block types is easy as the observation space expands (using one-hot encoding) to accomodate new block types, but there is nothing special about them. (i.e. I am not encoding any special characteristics about the blocks themselves, just telling the neural network, here is block A at X/Y of type Z Z being one-hot encoded).
In summary, I am feeding the ‘current’ frame/state (with a bit of history thrown in) as observations (using encoded space as needed for block types) and the RL agent (via an LSTM) has to predict the actions (log-probabilities). I would then train this neural network as part of PPO which I describe next.
Training with Puffer
Puffer is an excellent library that comes with batteries included: from a full PPO implementation with a custom advantage function to dashboards, logging, hyperparameter sweeping etc.
My env (game) ended up being slow to train, so I ended up making Puffer faster (~5-10x for my use-case and in general scales sub-linearly with CPU/GPU cores/bandwidth). TL;DR: I added native multi-threading eval+train loop with GPU batching among other improvements. I will cover these in more depth in a future post.
I used my customized version of Puffer to train my pixel platformer.
I recommend following Joseph’s work as he broadcasts live his coding pretty much everyday.
Training a pixel platformer with moving platforms, and characters with weapons, switch activators, walls and rewards and goals is actually pretty hard: An agent has to figure out things like ‘here is a platform that is moving towards me, I need to jump right here to catch it, and oh by the way, watch out as I might get squished between the platform and the wall’.
I made each block-type/behavior be independent: a block reacts to and apply actions from neighboring blocks’ behaviors independently without needing an oracle. (A very similar idea borrowed from Spelunky). This helps keep the platformer feel natural where behaviors might emerge that we might otherwise not expect (“I pushed this block on top of an enemy and it got squished.” or “have a player pick an Item that could be a Weapon that shoots Lasers that can kill Enemies” etc.).
But this also makes the training very hard as (a) the behaviors are very fluid (b) there are many maps + many combinatorial behaviors, (c) and the agent needs to react to all these in real-time in a very short amount of time.
This was a very hard challenge - it’s still ongoing as the training is still not quite ‘superhuman’ yet.
Here are a bunch of tricks I used to train this demo platformer with Puffer:
Syllabus/Curriculum training
I used a ramp-up set of lessons that an agent (or a thousand of them, all in parallel) must ladder-climb to receive rewards over time. Here is series of graphs from WandB that explain this in a beautiful story (words can’t do justice):
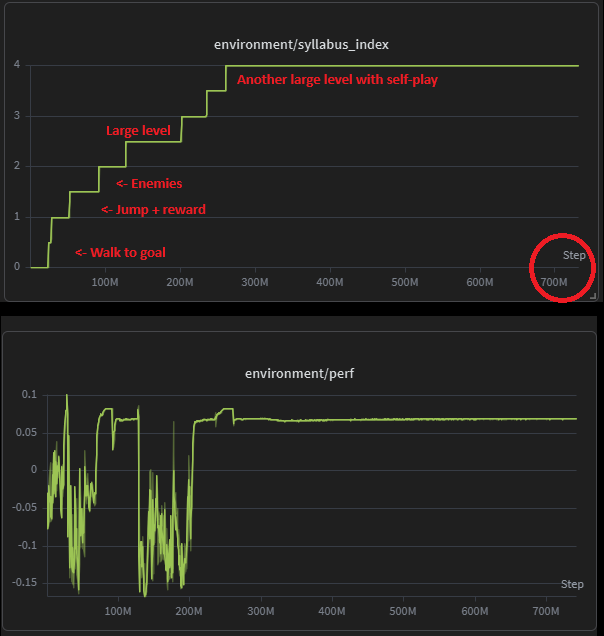
This worked out really well for my use-case as the agent can ramp-up learning.
NOTE: It’s not all good though: If you ramp-down (i.e. thrown in a simple level after learning a complex level), the agent will completely fall apart. RL is really finicky - it’s like teaching a super-smart but essentially a dum-dum machine. Sometimes the probabilities and all the stars line up; other times, not so much. Experimentation and sweeps help - it’s very time consuming as the env might change and you need to re-run this.
Self-play
To make it actually playable against a human, I wanted the agent to learn the dynamics of playing against another player. I used the self-play game mechanic here: record player 1’s (the agent) actions in time T, and replay it in time T+1 on player 1 to train player 2 (another episode essentially):

There are several cool properties/implications from this:
-
The game is essentially recordable/replayable via pure actions.
- i.e. the entire game is deterministic in that, replaying the actions (with the correct random seed/fixed time-step) will always result in the same states over the same timesteps.
-
You can record a human’s actions and make them play against a ghost of their own. This is super fun and you can try in the demo above.
- This is what the RL agent might ‘feel’ like during training?
-
You can also record the RL training agent (as a sparse record, as we are training at 100K+ FPS!), and view it in action to debug/visualize the training. It looks really fun:
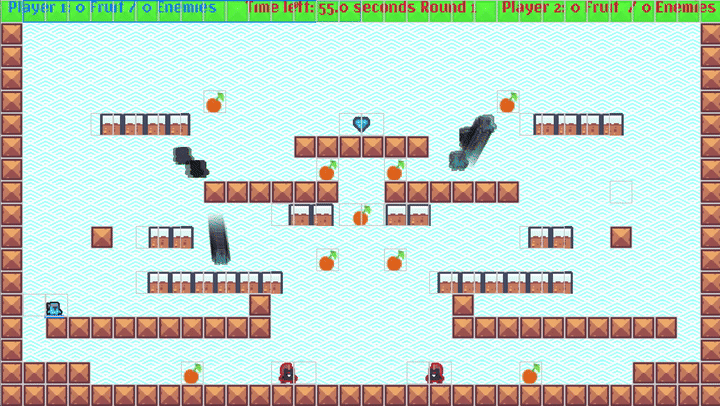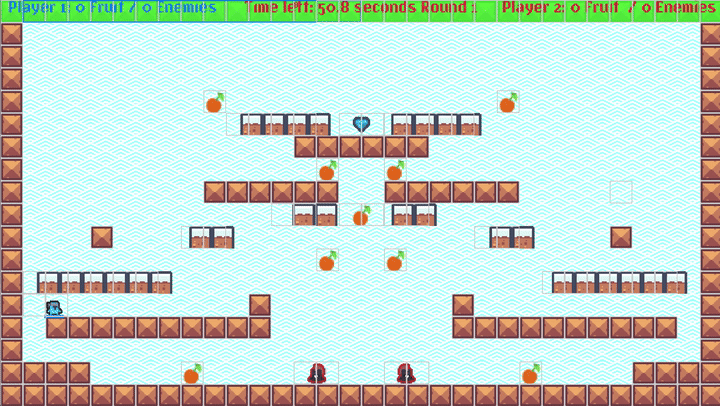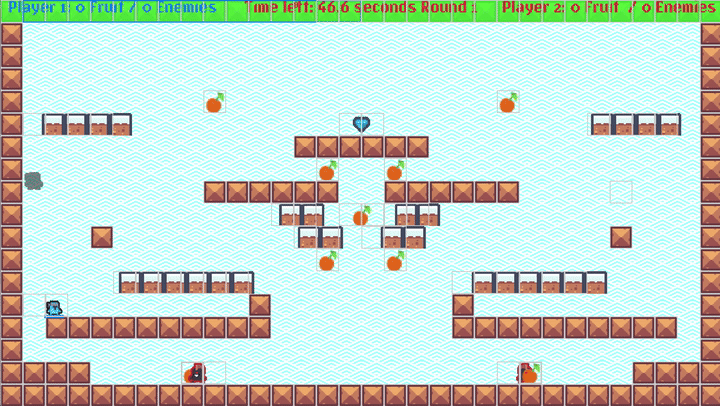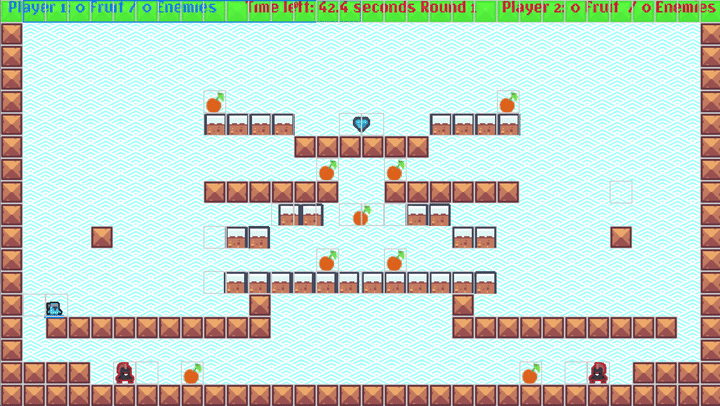
NOTE: The GIF above has a nice
Move 37-like feel: Watch the blinking guy at the bottom left - that little dude figures out a bug in my platformer logic and stands/jumps on top of the wall blocks awkwardly and reaches the goal!
- You could also potentially have async multiplayer by matchmaking with other players by recording their actions and playing them against
you. (There are several such ideas here that are very interesting for the future…)
Other tricks
-
Delayed gratification: Withold rewards until after the agent reaches the goal. This (coupled with syllabus training) helps make magic happen. It’s incredibly hard to learn to jump around, get on a moving platform, collect rewards (and understand how the other player is collecting rewards too, as we want to “beat ‘em”) and finally reach the goal, all in one go. Instead, by first learning to walk, then jump around, collect rewards, get on a moving platform, etc, the agent sort accumulates knowledge over a syllabus. It’s then possible to say things like: “you only get to see rewards at the end of the episode and not see intermediate rewards at all”. And this surprisingly works well (only when combined with curriculum learning).
-
Obs space is expanded out from the agent’s perspective: I sort the blocks by how close they are to the agent and that helps the agent understand what’s ‘near’ and what’s ‘far’ (or unimportant). It also makes it easier for the agent to plan around enemies that might be bothering it versus planning to reach the goal that might be farther away. (There are a bunch of other gnarly tricks here that might require a blog post on their own). Note that obs space is fixed (max across all levels), which means if I have a simple level with just a few blocks, I still need to encode a bunch of empty obs for the otherwise ‘missing’ blocks.
-
Hyperparam sweeps: It was incredibly hard to train at the beginning because of needing to fiddling with the various hyperparameters. Thankfully Puffer has builtin Protein-based sweeps (and coupled with my much faster eval+training loop), so finding the right hypers was much easier (just let the machine spin for a day or two).
Final thoughts
The pixel platformer demo is now playable: I think it’s actually cool to either try self-play (to play against your time-ghost) or play against the RL agent.
Granted, the current RL trained agent is not fully up to the bar (yet), so it’s an ongoing process to make this more and more enjoyable/playable RL agent as I get better at learning and using RL.
Games are a really good way to learn hard technical stuff - I also hope the game demo is a standalone artifact in and of itself. I do hope this translates to something more meaningful in the physical world as RL seems very, very potent and useful when done carefully and in a performant way - an individual developer can run these RL simulations on commodity hardware without much capital infusion - which is quite amazing given the compute needs to train an LLM (would be a small country’s GDP by now).
Note that all of my work was done in a local machine with no cloud training etc, which is quite amazing to know how powerful these GPUs are these days.
Next up: I will next write (a much larger) post on the actual RL eval+training optimizations I pursued to make this whole process much faster so that I could run experiments in a couple of hours instead of the prior 10-12 hour runs.